In 2026, every AI tool promises that your data is "encrypted at rest." But for developers building stateful AI agents in healthcare, finance, or enterprise SaaS, "encrypted at rest" is often just security theater.
Why? Because traditional AI memory databases (Vector DBs and RAG pipelines) have a fatal flaw: to search your data, the database has to be able to read your data.
If your cloud provider can run a semantic search or a keyword match on your users' memories, they store it in plain text. If they are breached, or if an insider goes rogue, your users' most private thoughts, financial records, and proprietary code are exposed.
At Maple Memory, we realized that true sovereign AI requires a new paradigm: Searchable Encryption.
The Paradox of Encrypted RAG
Standard AES-256 encryption is fantastic at turning a sentence like "The user's API key is sk_live_123"
into cryptographic noise like gAAAAABk7y....
The problem is that you cannot run a SQL LIKE query or a cosine similarity vector search on random noise. The math breaks.
To solve this, most memory providers compromise. They decrypt the data in the database layer right before searching, exposing the plaintext in their own system logs and memory heaps.
The Maple Memory Solution: Blind Indexing
We built Maple Memory on a Zero-Knowledge architecture. We mathematically cannot read your users' conversations, yet we can still search them in under 250 milliseconds.
We achieve this through a cryptographic technique called Blind Indexing.
Instead of searching the encrypted ciphertext, Maple Memory creates a separate, highly secure "Search Index" using HMAC-SHA256 hashing.
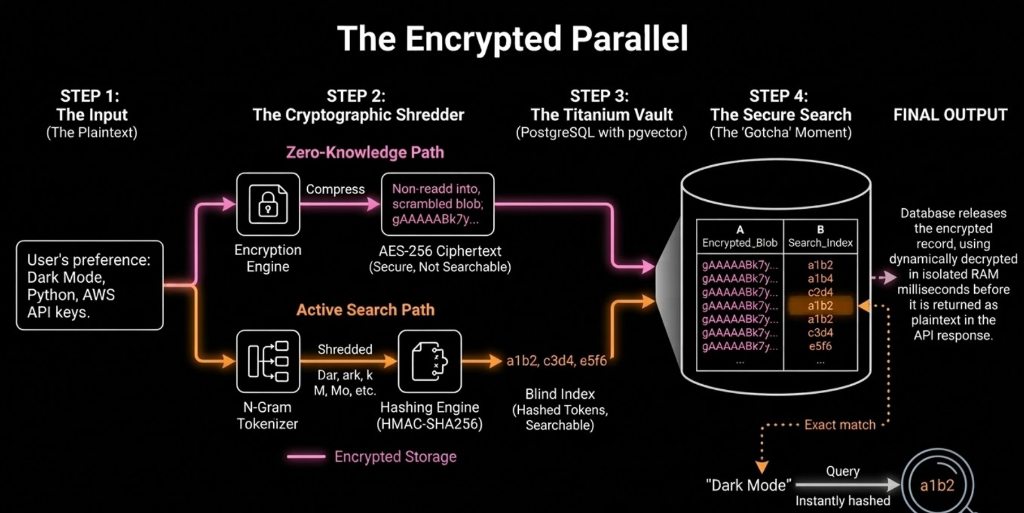
Visualizing Blind Indexing: How Maple Memory’s Zero-Knowledge RAG architecture performs precise, typo-tolerant FTS searches on mathematical hashes while the actual data remains locked in application-level AES-256 ciphertext.
Here is how the pipeline works:
- The Digital Shredder (RAM-Only): When your user sends a message, the plaintext hits our secure worker. It exists only in isolated temporary RAM.
- N-Gram Tokenization: We break the text down into overlapping, 3-character chunks
(trigrams). The word "Docker" becomes
doc,ock,cke,ker. - Cryptographic Hashing: We hash each individual chunk using a unique Blind Index
Key.
docbecomesa1b2c3.... - Storage & Shredding: We save the fully AES-256 encrypted memory node alongside the list of hashes. Then, the RAM is physically wiped. No plaintext ever touches our hard drives or logs.
Typo-Tolerant, Zero-Knowledge Search
When your agent needs to retrieve a memory, you send the query. We hash the search terms using the same exact method and look for matching hashes in the database.
Because we use N-Gram hashing, we are the only AI memory provider that can perform Fuzzy Matching (typo
tolerance) on fully encrypted data. If a user searches for "Doker", the hashes for dok and
ker will still trigger a match against the encrypted record for "Docker".
The database engine retrieves the encrypted blobs incredibly fast (sub-250ms), and the final decryption happens dynamically, safely inside the isolated worker environment just milliseconds before it is returned to your API.
Eliminate Your "Privacy Debt"
Building AI agents shouldn't require you to take on massive compliance liabilities.
By offloading your agent's memory to Maple Memory, you are adopting an infrastructure that makes SOC2 and HIPAA compliance drastically simpler. If a bad actor were to somehow steal our entire database, they would walk away with mathematically useless arrays of hashes and AES-256 ciphertext.
Stop hoarding plaintext. Give your AI perfect memory, and give your users perfect privacy.