The open-source AI revolution gave us the ability to run incredibly powerful models entirely on our own hardware. With tools like Ollama and vLLM, developers in 2026 can spin up local LLMs that rival cloud giants.
We achieved Model Sovereignty. But we forgot about Data Sovereignty.
If your local, private AI assistant still relies on a centralized, unencrypted vector database in the cloud to remember its conversations, it isn't truly sovereign. You’ve just moved the privacy leak from the model to the memory layer.
To build a genuinely Sovereign AI, an assistant where the user has absolute ownership and control over their "digital brain", you need a Local-First Memory Infrastructure.
Here is how to build one.
The Problem with Cloud RAG for Private Agents
Most developers default to standard cloud vector databases for their RAG (Retrieval-Augmented Generation) pipelines. But for personal AI assistants, healthcare bots, or internal enterprise agents, this is a fatal architectural flaw.
When an AI remembers your user's financial anxiety, their proprietary code snippets, or their personal relationships, that data is infinitely more sensitive than the initial prompt. Sending that rich, interconnected context to a multi-tenant cloud database where it sits in plaintext is a massive liability.
A truly Sovereign AI operates on a simple rule: The memory belongs to the user, and the infrastructure provider should be mathematically blind to it.
The Local-First Memory Paradigm
At Maple Memory, we designed our memory engine for strict data sovereignty. Whether you are using our cloud API or our local-deployment version, the principles of Sovereign AI remain identical:
- Zero-Logging & The "Blindfolded Middleman": If you use the Maple Memory API to power your local agent's memory, we operate strictly as a blindfolded processor. The moment your user's text is converted into our Cognitive Graph, it is processed in isolated RAM (our "Digital Shredder") and encrypted using AES-256 before it ever hits a disk. We don't write your prompts to our logs. If it's not in the logs, it can't be leaked.
- Absolute Tenant Isolation: Standard databases dump everyone's vectors into the same pool and filter them by ID. Maple Memory enforces strict, cryptographic User Isolation. Every user's Contextual Memory Graph is siloed. It is mathematically impossible for a search query to cross-pollinate memories between users.
- True Local Infrastructure Deployment: For enterprise developers and privacy-absolutists, Maple Memory's local version can be deployed directly within your own VPC or private infrastructure. Your data never leaves your environment. You get the intelligence of our Autonomous Routing (Isolate, Branch, Merge) without ever sending a single packet over the public internet.
The Architecture of a Sovereign AI Agent
Building this is easier than you think. Here is the blueprint for a fully sovereign stack in 2026:
- The Brain (LLM): A local model (like Llama 3 or Mistral) running on your own hardware via Ollama or a private cloud instance.
- The Orchestrator: A lightweight Python/Node backend that handles the business logic and user interface.
- The Memory (Maple Memory): Your local or API-based Maple Memory instance.
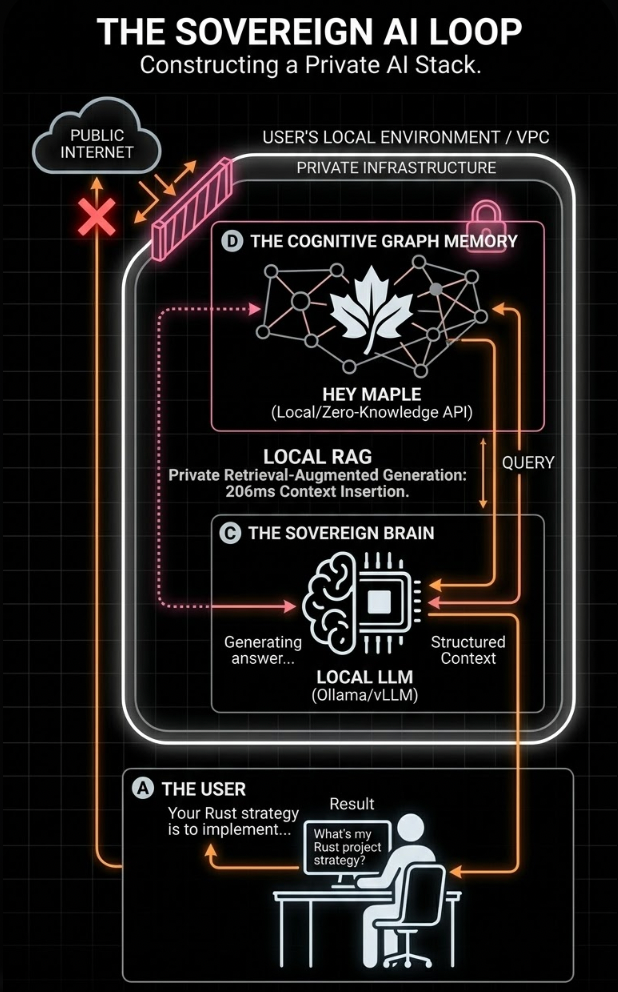
Visualizing Data Sovereignty: We build AI that remembers you, but we built a database that can't read you. Complete your local LLM stack with Maple Memory's Zero-Knowledge memory infrastructure.
The Workflow:
- The User Speaks: The user tells their local AI, "I want to rewrite my backend in Rust."
- Autonomous Routing: Your backend sends that text to Maple Memory. Our engine processes it, recognises it as a new "Branch" from their previous Python projects, and encrypts it into the graph.
- Local Retrieval: When the user asks, "What language am I migrating to?", Maple Memory performs a sub-250ms encrypted search and returns the exact context.
- Sovereign Generation: Your local LLM reads the context and generates the answer. At no point did Anthropic, Google, or even Maple Memory read the plaintext of that conversation.
Reclaiming the Digital Brain
We are building AI assistants that will act as our second brains, remembering the context of our lives and businesses for decades to come.
We cannot allow that level of intimate context to be harvested by standard cloud databases. By combining local LLMs with Maple Memory's zero-knowledge, local-first memory, you give your users the ultimate luxury: an AI that remembers everything, but tells no one.
Stop compromising on privacy. Build the next generation of sovereign agents today.